Vous avez choisi un modèle d'IA pour votre premier projet sérieux. Le piège n'est pas dans ce choix. Il est de construire toute votre architecture autour de lui.
Une architecture qui ne dépend pas d'un seul modèle, c'est une architecture conçue pour en changer sans tout réécrire : remplacer Claude par GPT, ou par un modèle libre installé chez vous, sans remettre en cause votre application. Voici pourquoi ce choix est probablement plus important que celui du modèle lui-même.
Le marché des modèles bouge trop vite pour qu'on s'y attache
Début 2026, près de 240 modèles sont évalués sur les grands bancs d'essai du secteur, d'après le recensement d'Incremys. Six mois plus tôt, ce paysage était différent. Six mois plus tard, il le sera encore.
Ce n'est pas un détail de veille techno. C'est la donnée centrale de toute décision d'architecture IA. Le prix d'un token (l'unité à laquelle se facture un modèle) s'effondre d'année en année à capacité égale. Mais la facture, elle, grimpe. Gartner le pointe : la consommation de tokens augmente plus vite que leur prix ne baisse, parce que les modèles qui raisonnent et les agents qui enchaînent les appels en consomment bien plus. Le coût total monte donc malgré la baisse unitaire. Raison de plus pour diriger chaque tâche vers le modèle le moins cher qui fait le travail.
Des modèles sont mis hors service avec quelques mois de préavis. Un acteur chinois ou un modèle libre rattrape, le temps d'un trimestre, le leader que vous aviez choisi.
Vous prenez votre décision sur une photo d'un marché qui rebat ses cartes tous les trimestres.
Les entreprises qui font tourner de l'IA en production sérieuse l'ont déjà intégré. Selon les données de Menlo Ventures, les organisations déploient typiquement trois modèles de fondation ou plus, en dirigeant chaque tâche vers le bon, précisément pour ne pas se lier à un seul fournisseur. Le mono-modèle n'est déjà plus la norme chez les équipes les plus avancées. S'y enfermer aujourd'hui, c'est une facture qu'on règle deux ans plus tard.
Ne branchez jamais votre application en direct sur un modèle
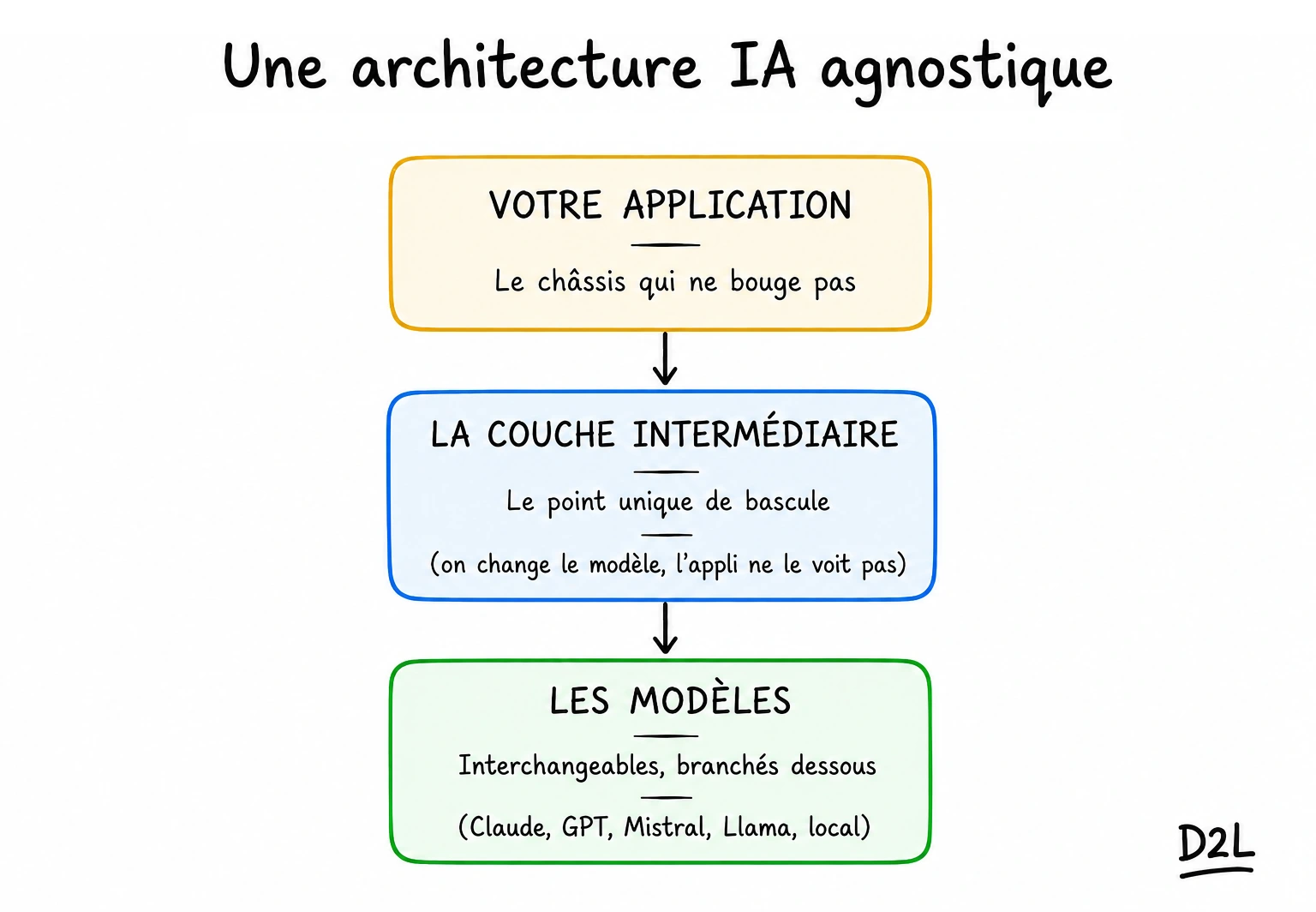
Le principe tient en une règle : votre application passe par un intermédiaire, une sorte de standard téléphonique. Elle lui adresse sa demande, lui la transmet au modèle du moment et rapporte la réponse, toujours dans le même format. Vous changez de modèle, l'intermédiaire reste, l'application ne s'aperçoit de rien. C'est ce que les architectes appellent une architecture « agnostique au modèle ».
Attention au contresens : ça ne veut pas dire « faites tourner dix modèles en parallèle ». Ça, c'est de la complexité gratuite. Ça veut dire une seule chose : derrière l'intermédiaire, on branche le modèle qu'on veut, et on en change sans toucher au reste.
Une telle architecture, c'est une voiture conçue pour qu'on puisse changer le moteur sans refaire la carrosserie. Le moteur, c'est le modèle. Le châssis, les sièges, le tableau de bord, c'est votre application. Le jour où un meilleur moteur sort, ou que le vôtre vous lâche, vous le remplacez en atelier sans reconstruire la voiture autour.
À l'inverse, voici à quoi ressemble une architecture qui se lie à un seul modèle, et qu'on croise hélas souvent :
- le code l'appelle partout, sans rien entre les deux ;
- les instructions données à l'agent sont taillées pour les manies d'un seul modèle, impossibles à rejouer ailleurs ;
- la logique métier suppose que la réponse arrivera toujours dans le format exact de ce modèle-là.
Le jour où vous voulez changer, ce n'est plus une bascule, c'est une réécriture.
Notre favori aujourd'hui ne sera peut-être pas celui de demain
Soyons clairs, on a un favori. Chez D2L, on s'appuie majoritairement sur Claude pour le développement, pour des raisons assumées : qualité du code produit, écosystème d'agents, transparence sur ses propres limites. Aujourd'hui, c'est l'outil qui nous donne les meilleurs résultats. Mais demain, ce sera peut-être GPT, Mistral, ou un acteur qui n'existe pas encore.
Faut-il pour autant lier le destin de l'architecture d'un client à un seul éditeur ? Sûrement pas. Choisir le meilleur outil du moment, c'est une décision opérationnelle. Pouvoir en changer sans douleur, c'est une décision d'architecture. S'appuyer sur un outil et faire dépendre de lui la survie d'un projet qu'on veut voir tourner huit ans, ce sont deux choses différentes : la première est un confort de travail, la seconde une faute d'architecture.
C'est ça, la posture qu'on défend : celle de l'architecte qui aime un outil sans enchaîner ses clients à un fournisseur. Ni le fanboy qui ne jure que par un modèle, ni le sceptique qui n'en branche aucun. Entre les deux, il y a la voie qui consiste à rester libre de profiter du meilleur, au fur et à mesure qu'il arrive.
Ce que cette liberté coûte, et quand elle ne vaut pas le coup
On ne va pas vous vendre une recette sans contrepartie. Cette liberté a un prix, et le passer sous silence serait malhonnête.
Concevoir cette couche intermédiaire demande un peu plus d'ingénierie au démarrage qu'un branchement direct. Elle impose aussi une petite discipline : avant d'utiliser la fonctionnalité propriétaire la plus clinquante d'un fournisseur, on se demande si on saura s'en passer le jour où on changera. Parfois on renonce à un gadget pour garder sa liberté. C'est un arbitrage, pas un dogme.
Et il y a des cas où ça ne vaut pas le coup. Un prototype jetable, un script interne qu'on lance une fois, une démonstration pour convaincre en interne : inutile d'y mettre une couche d'abstraction. On branche en direct, on avance, on jette. Cette indépendance, c'est pour ce qui part en production et doit durer. Pas pour ce qui vivra trois jours.
Cinq points à verrouiller pour rester libre
Voici, en pratique, l'ossature d'une architecture IA qui ne vous enferme pas. Cinq points à poser dès le cadrage. Aucun n'est sorcier. Tous coûtent dix fois plus cher à rattraper après coup.
Une couche d'abstraction entre votre application et le modèle
Jamais d'appel direct à un fournisseur dans votre code métier : tout passe par un point unique, qu'on peut rediriger.
Des instructions versionnées et documentées
Les consignes données à l'agent ne vivent pas enfouies dans le code. On les garde au propre, traçables, prêtes à être rejouées et réglées sur un autre modèle.
Un format de sortie que vous imposez
C'est vous qui définissez la structure de la réponse attendue, un JSON strict par exemple, pas le modèle. Le jour où vous changez, ce format imposé ne bouge pas, et le reste de l'application non plus.
De la mesure, modèle par modèle
On mesure le coût, la latence (le temps de réponse) et le taux d'erreur de chaque modèle. Sans ces chiffres, une bascule se décide à l'intuition. Avec, elle se décide sur des faits.
Un garde-fou qui ne dépend pas du modèle
Ne laissez jamais le modèle juger seul ses propres réponses. Entre sa réponse et l'action, glissez une vérification qui vous appartient : une règle métier, une comparaison à une source fiable, ou un seuil de confiance en dessous duquel on passe la main à un humain (la couche qui sait dire « je ne sais pas », dont on parlait dans le premier article de notre blog). Comme ce garde-fou vit dans votre code et pas dans le modèle, il protège de la même manière quel que soit le moteur branché derrière. C'est lui qui vous laisse changer de modèle sans refaire confiance à zéro.
Posez ces cinq points et vous avez une architecture qui transforme chaque progrès du marché en opportunité, là où une architecture mono-modèle le subit comme une menace.
Le bon modèle d'aujourd'hui sera dépassé. C'est mécanique, et c'est tant mieux. Une architecture qui ne dépend d'aucun modèle, c'est la seule manière de profiter de chaque avancée sans devoir se renier à chaque fois. On choisit un modèle. On n'épouse pas de fournisseur.