Un recruteur intercepte un passant à la sortie d'une bouche de métro, propose de s'engager au profit d'une grande ONG, fait signer un bulletin de soutien sur tablette, repart vers le suivant. Au même moment, sur un serveur dans un datacenter quelque part, un modèle de langage compare l'adresse saisie sur la tablette avec une base ouverte qui répertorie chaque rue et chaque numéro de France. Quand l'adresse colle, l'engagement file vers le contrôle qualité. Quand elle cloche, l'agent propose une correction. Quand rien ne tient, il passe la main à un humain.
Voilà à quoi ressemble un agent IA quand il rend service. Ça tourne, ça sert, ça ne fait pas de bruit. Bonne nouvelle : c'est moins compliqué que les conférences le laissent entendre. Mauvaise nouvelle : c'est aussi moins automatique.
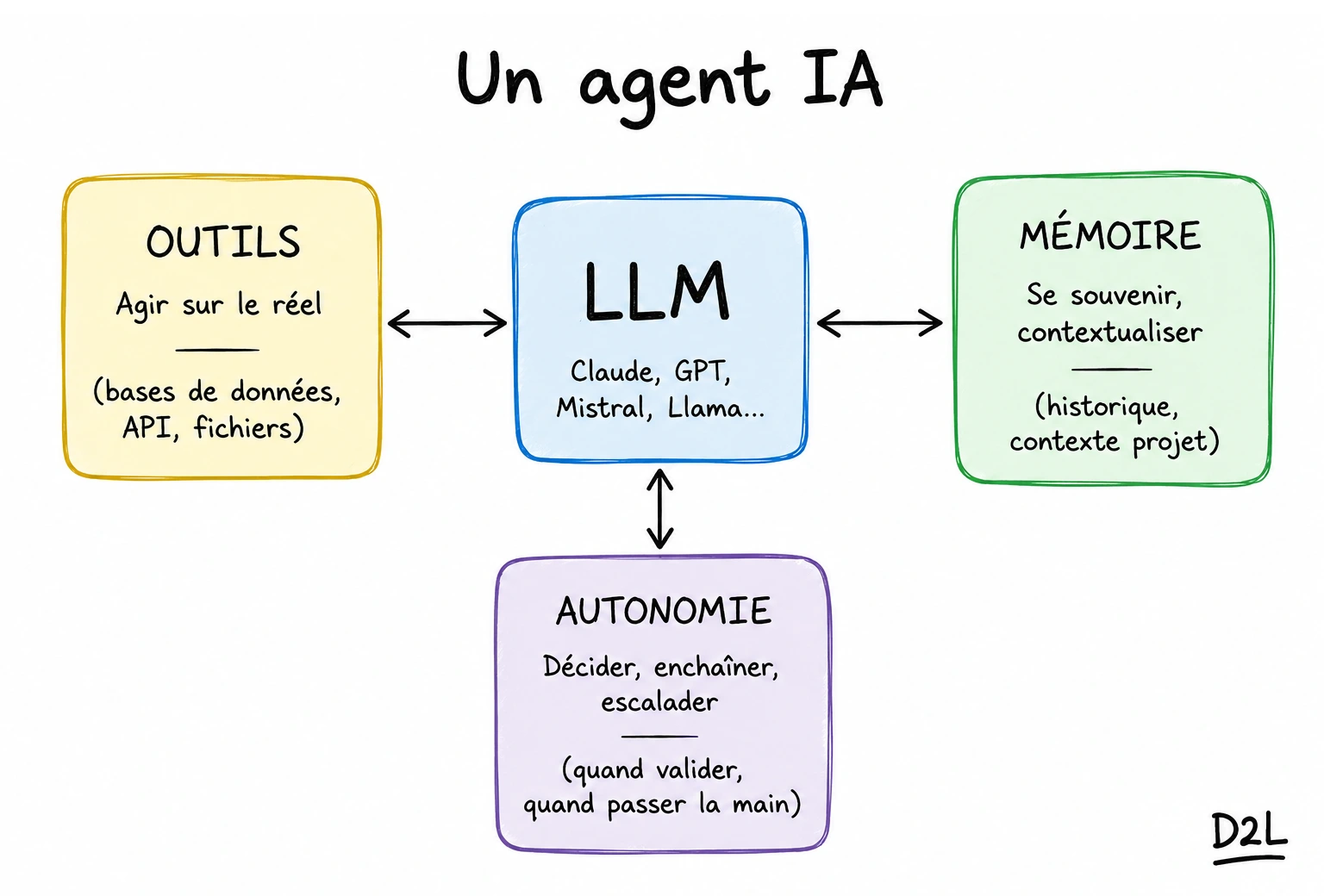
Un agent IA, c'est un LLM avec trois choses en plus
Un agent IA, c'est un modèle de langage (un LLM, pour Large Language Model, la famille à laquelle appartiennent Claude, GPT, Mistral, Llama) auquel on a ajouté trois capacités :
- des outils pour agir sur le réel,
- une mémoire pour se souvenir de ce qui s'est passé avant,
- l'autonomie pour enchaîner plusieurs étapes vers un objectif, sans qu'on ait à le piloter pas à pas.
Métaphore : un LLM seul, c'est un cerveau sans mains. Il sait expliquer, résumer, raisonner, proposer. Mais il ne peut ni ouvrir un dossier, ni vérifier une donnée, ni déclencher une action. L'agent IA, c'est ce même cerveau relié à des outils pour agir, à de la mémoire pour durer, à un environnement réel où ses décisions comptent.
L'outil, ici, c'est l'accès à une base nationale d'adresses. L'agent peut lui poser une question (ce numéro existe-t-il dans cette rue ?) et recevoir une réponse vérifiable. Sans cet outil, le modèle inventerait. Plausiblement, mais il inventerait. Et plausible n'est pas vrai.
La mémoire, dans ce cas précis, est minimaliste. L'agent traite chaque adresse indépendamment des précédentes. Sur d'autres tâches, comme un agent qui suit un dossier client sur trois semaines, elle devient centrale.
L'autonomie, c'est ce qui transforme le tout en agent. Le modèle décide seul quand il a une certitude (et accepte l'adresse), quand il a un doute (et propose une correction), quand il faut renoncer et passer la main à un humain (parce que rien ne colle). Une fois cadré, ça tourne.
Ce qui distingue un agent d'un chatbot
Un chatbot répond. Vous tapez une question, il génère une réponse, il attend la suivante. Un agent agit. Vous lui donnez un objectif, il enchaîne des actions sur le réel pour l'atteindre, il revient avec un résultat, ou avec une demande d'aide.
Le chatbot reste confiné à la fenêtre où il vous répond. L'agent opère dans votre système d'information.
C'est aussi pour ça qu'on peut faire tourner un agent efficace avec un modèle d'IA gratuit et libre d'usage (open source), installé directement sur les serveurs de l'entreprise. Pas besoin d'envoyer ses données dans le cloud d'un grand fournisseur américain. Pour beaucoup d'entreprises, c'est un argument décisif : maîtrise des coûts, données qui ne sortent pas de chez soi, et indépendance vis-à-vis d'un acteur qui peut changer ses tarifs ou ses conditions du jour au lendemain.
Un agent ou plusieurs : par où commencer ?
Quand on parle d'agents IA aujourd'hui, on désigne deux réalités très différentes.
La première, c'est notre exemple d'ouverture : un modèle, un outil, une décision répétée à grande échelle. Ça tient en quelques jours de mise en place, ça tourne pendant des années.
La seconde, c'est une orchestration de plusieurs modèles spécialisés qui se passent la main, s'arbitrent, escaladent. Ça impressionne en démonstration. Ça coûte cher à fiabiliser en production.
Le mouvement le plus sain va du premier vers le second. On commence par un modèle, un outil, une décision. On industrialise, on observe, on apprend. Plus tard, peut-être, on ajoute un deuxième agent qui se passe la main avec le premier. La promesse de l'orchestration multi-agents tient quand la mécanique de base tient. Pas avant.
Trois cas où un agent tient ses promesses
En production, trois familles d'usage reviennent systématiquement parce qu'elles cochent les trois mêmes cases : un volume qui justifie l'investissement, une source d'information de référence accessible, un humain disponible pour les cas qui sortent du cadre.
La qualification et la priorisation de prospects
Un agent qui ouvre une centaine de profils par session, croise vos critères, remonte les quatre ou cinq qui valent un appel.
La validation et la correction de données
C'est notre exemple d'ouverture, mais ça marche pour les IBAN, les SIRET, les codes produits, les références fournisseurs. Cela marche partout où des humains saisissent des données dans un système, et où il faut s'assurer que ces données soient justes avant de les utiliser plus loin. Volume élevé, règles claires, source de référence disponible. Les trois conditions sont réunies.
La synthèse documentaire à grand volume
Lecture de 200 CV pour un poste, de 50 rapports d'expertise, de 1 000 réponses à un questionnaire ouvert. L'agent fait une première passe, classe, résume, signale ce qui mérite l'œil humain. Vous gagnez la phase de tri, qui est la plus chronophage et la moins rémunératrice. Sur les CV en particulier, la lecture humaine reste obligatoire à l'arrivée : tri assisté oui, décision automatique non.
Trois pièges à ne pas sous-estimer
Premier piège : déléguer à l'agent une décision qui demande du jugement humain. Un chatbot qui répond seul à une question juridique sensible, un scoring de crédit qui tranche sans audit, un agent qui valide un paiement au-delà d'un seuil. La règle est simple. Si la décision a un coût élevé en cas d'erreur, l'agent prépare, l'humain tranche. Pas l'inverse.
Deuxième piège : sous-estimer la maintenance. On l'apprend nous-mêmes en ce moment, sur nos propres outils. Un agent en production, ce n'est pas un produit qu'on installe et qu'on oublie. Les instructions données à l'agent vieillissent (les modèles changent, les outils changent), les sources d'information évoluent, les résultats dérivent. Il faut surveiller, ajuster, relancer. Selon l'étude State of AI in the Enterprise 2026 de Deloitte, seule une entreprise sur cinq dispose aujourd'hui d'un modèle mature de gouvernance de ses agents IA. La mise en place est presque la partie facile. La maintenance demande autant d'attention que la mise en place, et à prévoir dans le budget dès le premier jour. C'est probablement le piège le plus sous-estimé du marché.
Troisième piège : laisser l'agent halluciner en silence. Un agent qui génère une réponse plausible sans savoir ce qu'il avance, et personne ne le remarque avant qu'un client le découvre. La parade ne tient pas dans la qualité du modèle. Elle tient dans la connexion à des sources fiables (votre catalogue produit, votre fichier client, une base ouverte) et dans une couche de validation qui sait dire « je ne sais pas ». Mieux vaut un agent qui passe la main à un humain dans 15 % des cas qu'un agent qui se trompe en silence dans 3 %.
Le réflexe avant tout projet IA
Avant de demander quel modèle, quelle plateforme, quel framework, posez-vous celle-ci : quelle tâche dans votre entreprise est à la fois répétitive, mesurable, et tolérante à l'erreur partielle ?
- Répétitif. Le même type de tâche, plusieurs fois par jour ou par semaine. Si c'est unique, le retour sur investissement ne sera jamais là.
- Mesurable. Vous savez compter combien de fois c'est fait, combien ça coûte aujourd'hui. Vous saurez compter combien ça coûte après. Sans métrique, vous ne saurez pas si ça marche.
- Tolérant à l'erreur partielle. Une erreur ne fait pas écrouler le système. Vous pouvez rattraper. Si la moindre erreur est catastrophique (santé, juridique, financier critique), l'IA peut rester en assistance, mais c'est l'humain qui décide. Pas un agent en pilotage automatique.
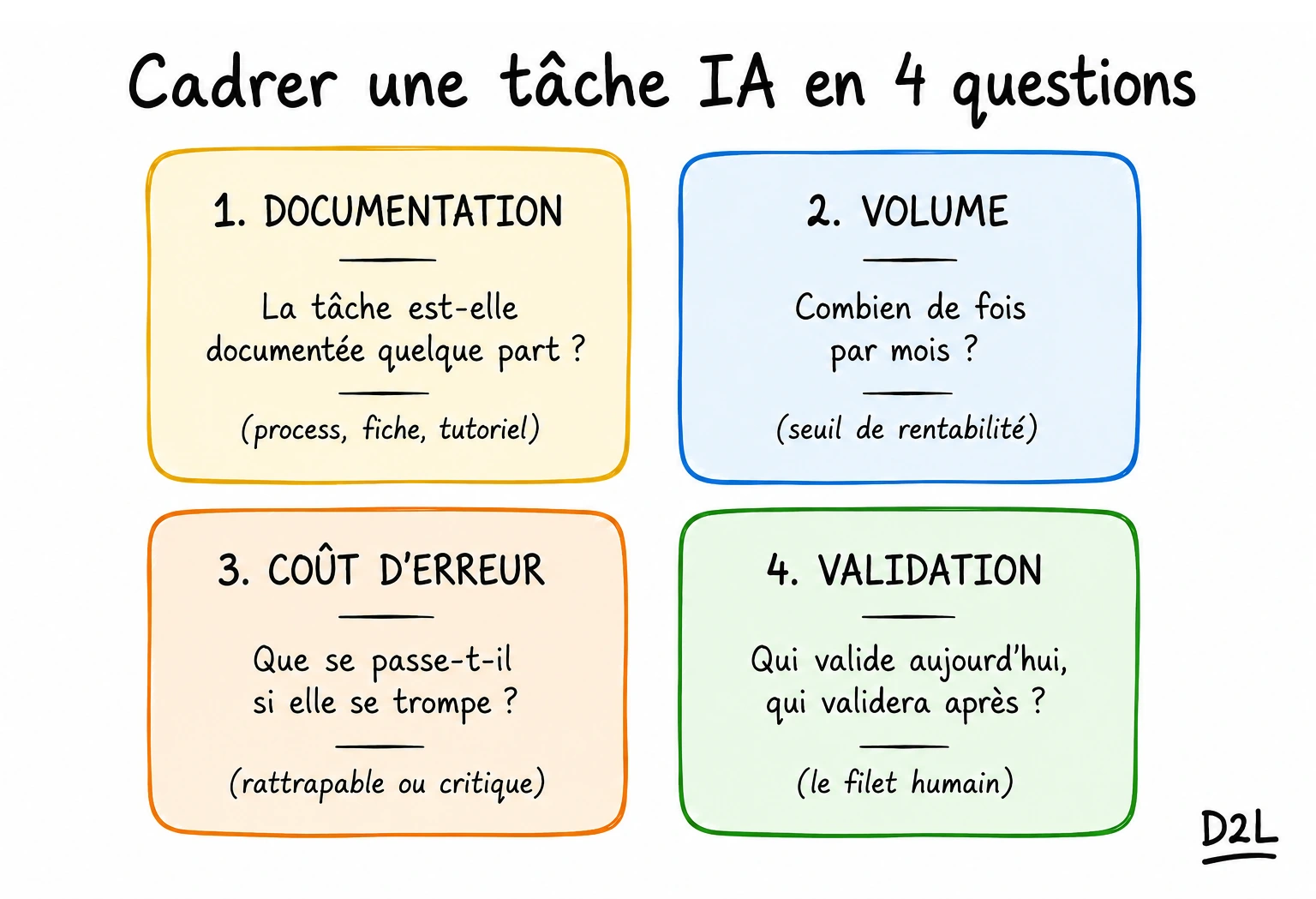
Une fois qu'une tâche coche les trois cases, quatre questions de cadrage suffisent pour démarrer :
- La tâche est-elle documentée quelque part ?
- Combien de fois est-elle exécutée par mois ?
- Quel est le coût d'une erreur ?
- Qui valide aujourd'hui, et qui validera après ?
Ce qui tourne, vraiment
Les meilleurs agents sont souvent invisibles. Ils tournent en arrière-plan, corrigent, vérifient, relancent, priorisent, classent, escaladent.
L'exemple qui ouvre cet article n'est pas tombé du ciel. Cette mécanique de scoring d'adresses tourne en production depuis presque 3 ans pour un opérateur français de la collecte de dons, dont nous opérons la plateforme depuis plus de 10 ans. 140 000+ donateurs passés par le système. 60 % d'adresses redressées automatiquement sur la syntaxe, 8 % corrigées sur des incohérences détectées. Moins de 1 % de dossiers finissent en correction humaine. Aucune fanfare.
Sources
- Deloitte State of AI in the Enterprise 2026